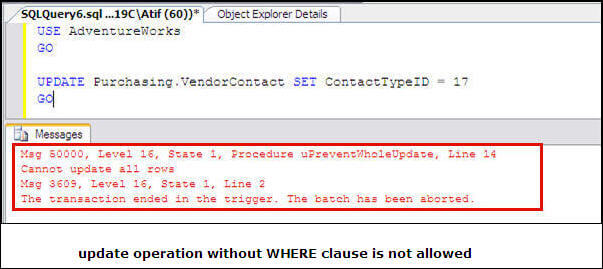
After Update Trigger Sql Server For Each Row In Range
Understanding how SQL Server executes a query. If you are a developer writing applications that use SQL Server and you are wondering what exactly happens when you . The only way to interact with the back- end database is by sending requests that contain commands for the database. The protocol used to communicate between your application and the database is called TDS (Tabular Data Sream) and is described on MSDN in the Technical Document . The application can use one of the several client- side implementations of the protocol: the CLR managed Sql.
Client, Ole. DB, ODBC, JDBC, PHP Driver for SQL Server or the open source Free. TDS implementation. The gist of it is that when your application whats the database to do anything it will send a request over the TDS protocol. The request itself can take several forms: Batch Request. This request type contains just T- SQL text for a batch to be executed. This type of requests do not have parameters, but obviously the T- SQL batch itself can contain local variables declarations. This is the type of request Sql.
This article presents those. I have two table. One is customer. I want to create a trigger that will execute after update in customer. Error Handling in SQL 2000 – a Background. An SQL text by Erland Sommarskog, SQL Server MVP. Last revision 2009-11-29. This is one of two articles about error.
Locking is a major part of every RDBMS and is important to know about. Adobe Flash Standalone Installer Filehippo Download. It is a database functionality which without a multi-user environment could not work. Introduction. Sometimes you'd like the SQL Server itself to automatically generate a sequence for entities in your table as they are created. For example, assigning.
Client sends if you invoke any of the Sql. Command. Execute. Reader(), Execute. Non. Query(), Execute. Scalar(), Execute. Xml. Reader() (or they respective asyncronous equivalents) on a Sql.
Command object with an empty Parameters list. Office Starter Download Free Xp Updates. If you monitor with SQL Profiler you will see an SQL: Batch.
Starting Event Class. Remote Procedure Call Request. This request type contains a procedure identifier to execute, along with any number of parameters. In this case the first parameter is the T- SQL text to execute, and this is the request that what your application will send if you execute a Sql. Command object with a non- empty Parameters list. If you monitor using SQL Profiler you will see an RPC: Starting Event Class. Bulk Load Request.
Bulk Load is a special type request used by bulk insert operations, like the bcp. IRowset. Fast. Load Ole. DB interface or by the Sql. Bulkcopy managed class. Bulk Load is different from the other requests because is the only request that starts execution before the request is complete on the TDS protocol. The list of requests in the server can be queried from sys.
For example if the request is a SQL Batch type request the task will represent the entire batch, not individual statements. Individual statements inside the SQL Batch will not create new tasks. Certain individual statements inside the batch may execute with parallelism (often referred to as DOP, Degree Of Parallelism) and in their case the task will spawn new sub- tasks for executing in parallel. If the request returns a result the batch is complete when the result is completely consumed by the client (eg. You can see the list of tasks in the server by querying sys.
At this stage the server has no idea yet what the request actually is. The task has to start executing first, and for this the engine must assign a worker to it.
Workers. Workers are the thread pool of SQL Server. A number of workers is created initially at server start up and more can be created on- demand up to the configured max worker threads. Only workers execute code.
Workers are waiting for PENDING tasks to become available (from requests coming into the server) and then each worker takes exactly one task and executes it. The worker is busy (occupied) until the task finishes completely.
Tasks that are PENDING when there are no more available workers will have to wait until one of the executing (running) task completes and the worker that executed that task becomes available to execute another pending task. For a SQL batch request the worker that picks up that task will execute the entire SQL batch (every statement). This should settle the often asked question whether statements in a SQL batch (=> request => task => worker) can execute in parallel: no, as they are executed on a single thread (=> worker) then each statement must complete before the next one starts. For statements that internally use parallelism (DOP > 1) and create sub- tasks, each sub- task goes through exactly the same cycle: it is created as PENDING and a worker must pick it up and execute it (a different worker from the SQL batch worker, that is by definition occupied!).
The lists and state of workers inside SQL Server can be seen by querying sys. At this stage SQL Server will behave much like an interpreted language VM: the T- SQL text inside the request will be parsed and an abstract syntax tree will be created to represent the request.
The entire request (batch) is parsed and compiled. If an error occurs at this stage, the requests terminates with a compilation error (the request is then complete, the task is done and the worker is free to pick up another pending task). SQL, and T- SQL, is a high end declarative language with extremely complex statements (think SELECT with several JOINs). Compilation of T- SQL batches does not result in executable code similar to native CPU instructions and not even similar to CLI instructions or JVM bytecode, but instead results primarily in data access plans (or query plans). These plans describe the way to open the tables and indexes, search and locate the rows of interest, and do any data manipulation as requested in the SQL batch. For instance a query plan will describe an access path like 'open index idx. As a side note: a common mistake done by developers is trying to come up with a single T- SQL query that cover many alternatives, usually by using clever expressions in the WHERE clause, often having many OR alternatives (eg.
For developers trying to keep things DRY and avoiding repetition are good practices, for SQL queries they are plain bad. The compilation has to come up with an access path that work for any value of the input parameters and the result is most often sub- optimal. I cannot close this side without urging you to read Dynamic Search Conditions in T- SQL if you want to learn more about this subject. Optimization. Speaking of choosing an optimal data access path, this is the next stage in the lifetime of the request: optimization.
In SQL, and in T- SQL, optimization means choosing the best the data access path from all the possible alternatives. Consider that if you have a simple query with join between two tables and each table has an additional index there are already 4 possible ways to access the data and the number of possibilities grows exponentially as the query complexity increases and more alternative access paths are available (basically, more indexes).
Add to this that the JOIN can be done using various strategies (nested loop, hash, merge) and you’ll see why optimization is such an important concept in SQL. SQL Server uses a cost based optimizer, meaning that it will consider all (or at least many) of the possible alternatives, try to make an educated guess about the cost of each alternative, and then choose the one with the lowest cost. Cost is calculated primarily by considering the size of data that would have to be read by each alternative.
In order to come up with these costs SQL Server needs to know the size of each table and the distribution of column values, which is are available from the statistics associated with the data. Other factors considered are the CPU consumption and the memory required for each plan alternative. Using formulas tuned over many years of experience all these factors are synthesized into a single cost value for each alternative and then the alternative with the lowest cost is chosen as the query plan to be used. Exploring all these alternatives can be time consuming and this is why once a query plan is created is also cached for future reuse. Future similar requests can skip the optimization phase if they can find an already compiled and optimized query plan in the SQL Server internal cache. For a lengthier discussion see Execution Plan Caching and Reuse.
Execution. Once a query plan is chosen by the Optimizer the request can start executing. The query plan gets translated into an actual execution tree.
Custom Auto- Generated Sequences with SQL Server. Introduction. Sometimes you'd like the SQL Server itself to automatically generate a sequence for entities in your table as they are created.
For example, assigning each new Customer added to your table a unique . There are effectively two ways to do using the built- in features that T- SQL provides. Identity. Columns - An identity is a common . An identity is simply an integer value that . You can specify when it should start and how it should increment when you add the column to your table: alter table Your. Table add ID int identity(start, increment) GUID Columns - A .
You can either use the NEWID() function when inserting into your table or set a default like this to implement a GUID column in your tables: alter table Your. Table add ID uniqueidentifier default newid() However, we often see questions in the forums regarding how to create other types of auto- generated sequences in tables.
For example, you might want your customers to automatically be assigned . It is clearly defining your specification and ensuring that it is logical and works for you. Before you can write code that will automatically generate sequences for you, you must consider. How many numbers will you ever need? Does your specification handle this?
Are they re- used? What happens to these values when the data does change? Does it make sense, then, to incorporate this data into your sequence algorithm? In this example, what comes after AA- 9. What comes after ? So, the very first step is to clearly, accurately, and completely define how your sequence values will be generated.
You must explicitly map out how to handle all possible situations and you must do some research to ensure that your specification will work for the data you are handling. A primary key of ? What people try to do here is to query the existing table to retrieve the last sequence value created, and then use that value to create the next one. Can you ensure that the same value is not generated for both processes?
This means that bulk imports, or moving data from production to testing and so on, might not be possible or might be very inefficient. If so, how efficient will it be? This function wouldn't work if called for each row in a single set- based INSERT - - each Next. Customer. Number() returned would be the same value. Overall, if this approach is absolutely required, then it's what you've got to do, but be sure that you consider the next two options first, which are much easier to implement and will generally work in most cases.
Looking at this closely, we see that it is really just simply a number from 1- x, formatted with leading zeroes to be 4 digits, and then prefixed with a . Which means that all the database needs to do is generate a number from 1- x, which means .. Do you really need to store it in the database as a VARCHAR? What does this gain? If you simply use an identity and return an integer to the front- end, it is trivial to format it with a . By doing this, you have all of the advantages of a built- in SQL Server generated identity value with none of the headaches - - no worries about concurrency, performance, set- based triggers, and so on. Or can I simply use that integer internally throughout the database and format it any way I want at my presentation layer?
This column can be stored in your table via a trigger, added as a computed column, or calculated using a View. You can implement it any way you wish. And this will work for set- based operations as well. First, let's create our Customers table like this: create table Customers. ID int identity not null primary key. Customer. Name varchar(1. Note that the db.
ID column is standard, database- generated identity which will be our physical primary key of the table. However, we will add a Customer. Number column which will be what we expose to the outside world in the . In this case, it is the same way you convert digits from decimal to hexadecimal or any other . Since we are working with a 4 .
To convert a number from 0- 2. A- Z, we add 6. 5 to it and use the CHAR() function, since the ASCII value of . We can do some simple testing like this to help us ensure that our function is working: select x, dbo. Customer. Number. AAAB. 2. 5 AAAZ.
AABA. 2. 7 AABB. AABZ. 5. 2 AACA. And that appears to do what we need. You should of course test the higher values as well.
How about. AA0. 00. This gives us 2. 6*2. The key is to identify and test the . The key is to make your logic entirely dependant on an integer value, and to map each integer value to a unique value in your designated sequence. By doing this, you are letting SQL Server do the hard part - - ensure that your keys are consistent and unique - - but now you have the flexibility of creating your .